


The Rise of Stochastic Parrots
AI’s Oppenheimer’s moment.
OpenAI’s ChatGPT has taken the world by storm, with 100 million users in its first two months. Is this an early indication of where true artificial intelligence (AI) will eventually lead us? Or are we just fooling ourselves with an elaborate toy that simply regurgitates our own biased thoughts and prejudices? Here’s a 100% human exploration of the subject.
What is a Large Language Model (LLM)?
A large language model is simply a statistical model trained to predict strings of text using a large amount of input. That’s all.
Another way of putting it is, “How does ChatGPT answer your question? It looks at past data to see how other people would have answered it in a similar fashion.” This calls to mind an old actuarial joke: “How many actuaries does it take to change a lightbulb?” Answer: “How many did it take last year?”.
This definition highlights the reliance of a LLM on two key factors:
- Training data: The raw ingredients to feed into the learning machine.
- Learning algorithm or model: The secret sauce that magically selects the “right” answer.
Notice that a language model is trying to produce an “approximate” or “similar” answer rather than the “exact” answer.
The guiding philosophy of the modern machine learning paradigm is about searching for — and hopefully finding — ever closer approximations to the truth through larger or “better” training data samples.
Instead of the previous failed AI approaches from the 1970s-80s, such as symbolic reasoning from the ground up or building exhaustive databases of expert systems, the current paradigm is about continuously adapting to relevant patterns in data – in other words, “learning from data”.
Stochastic Parrots
However, this statistical approximation from large data creates its own challenges. The term “stochastic parrots” was first introduced by Bender et al. (2021) in a sharp critique of LLMs to highlight the shortcomings and potential impacts of widespread adoption.
In a controversial series of events, Google — the employer of several of its co-authors — attempted to block the publication of the paper and threatened to fire its co-authors unless they withdrew the paper.[1]
This controversial “the Emperor has no clothes” moment has provoked an already heated debate. Now, let’s delve into why this occurred.
Figure 1: (Left) Size of model (number of parameters) increases ~10x per year (Right) Number of tokens seen during training
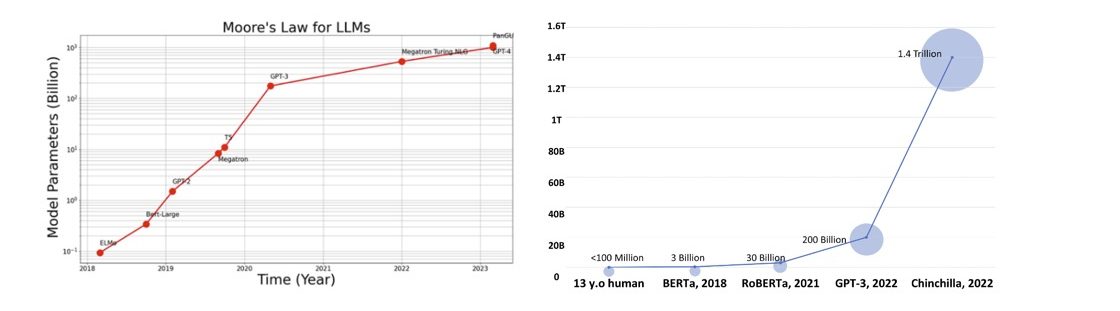
As seen in Figure 1, the size of language models has exploded in the past few years, as measured by the training data’s size and the number of model parameters. The competition is fierce as newer models show spectacular performance in setting records for ever more ambitious accuracy benchmarks.
However, the size of the training data doesn’t necessarily guarantee diversity. Large datasets often over-represent dominant viewpoints and under-represent minority and marginalized populations. As a result, LLMs reinforce stereotypical associations, such as racist, sexist and other discriminatory views. In terms of statistical jargon, the variance may decrease with larger training data samples, but the bias can remain.
Figure 2: GPT-3 training data sources
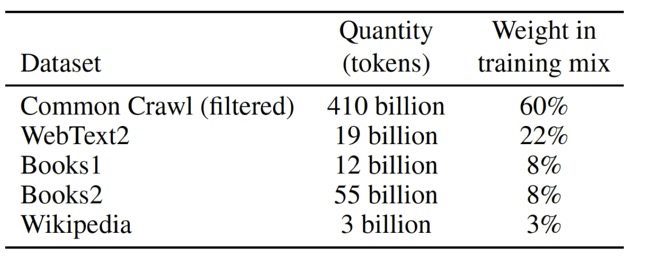
The proposed solution to this data quality problem is for a careful curation of training datasets rather than a passive trawling and ingestion of all the beauty and horrors that the World Wide Web has to offer.
As the old saying goes, “garbage in, garbage out”. However, such an approach is extremely resource-intensive with the debt burden of manual documentation. Figure 2 gives the proportional breakdown of each of the training data sources.
There is also the question of accountability in the chain of knowledge creation, both for upstream and downstream parties.
Whose intellectual property does the output of an LLM belong to? If this output is further used as the input for another future LLM query, then the chain of ownership becomes even more chaotic.
Also, would the developer of an LLM be exposed to liability from any potential losses suffered by the user? Who is to blame for errors made by the model or in the training data? Where does the buck finally stop?
Figure 3: Difference between Natural Language Processing and understanding

The authors question whether LLMs have made any real progress towards the grander long-term goal of Natural Language Understanding (NLU), arguing that these models are essentially “parroting” or regurgitating patterns seen in the data, rather than exhibiting true comprehension or understanding of natural language.
Bender & Koller (2020) take this further and argue that “human languages are linguistic systems that pair together form and meaning”.
LLMs, on the other hand, are fuelled by their training data, which contain only form without meaning. Instead of learning the causal structure of a language, LLMs are built purely on statistical associations between inputs and outputs, with no direct attribution of meaning to the data.
Given all the previous limitations, why are LLMs still so seductively popular amongst human users? One explanation is that language has been a tool reserved almost exclusively for human-to-human communication for at least the last 50,000 years of human evolution.
The sender and receiver of language messages have mutually shared intentions, contexts, and implicit meanings. The problem is, if one side of the communication (i.e., the computer) does not have meaning then the other side (the human) will instinctively try to interpret the implicit meaning or, if necessary, inject their own meaning into the message for clarity.
Bender et al. (2020) conclude that LLMs are far from being able to share such intentions, connections, and meanings – instead describe them as
“A system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot”.
Now, let’s review the very first “stochastic parrot”, a chatbot named ELIZA. Created almost 70 years ago, ELIZA was a cautionary tale of the dangers of anthropomorphising machines.
ELIZA: the first chatbot
Figure 4: ELIZA: an artificial psychotherapist
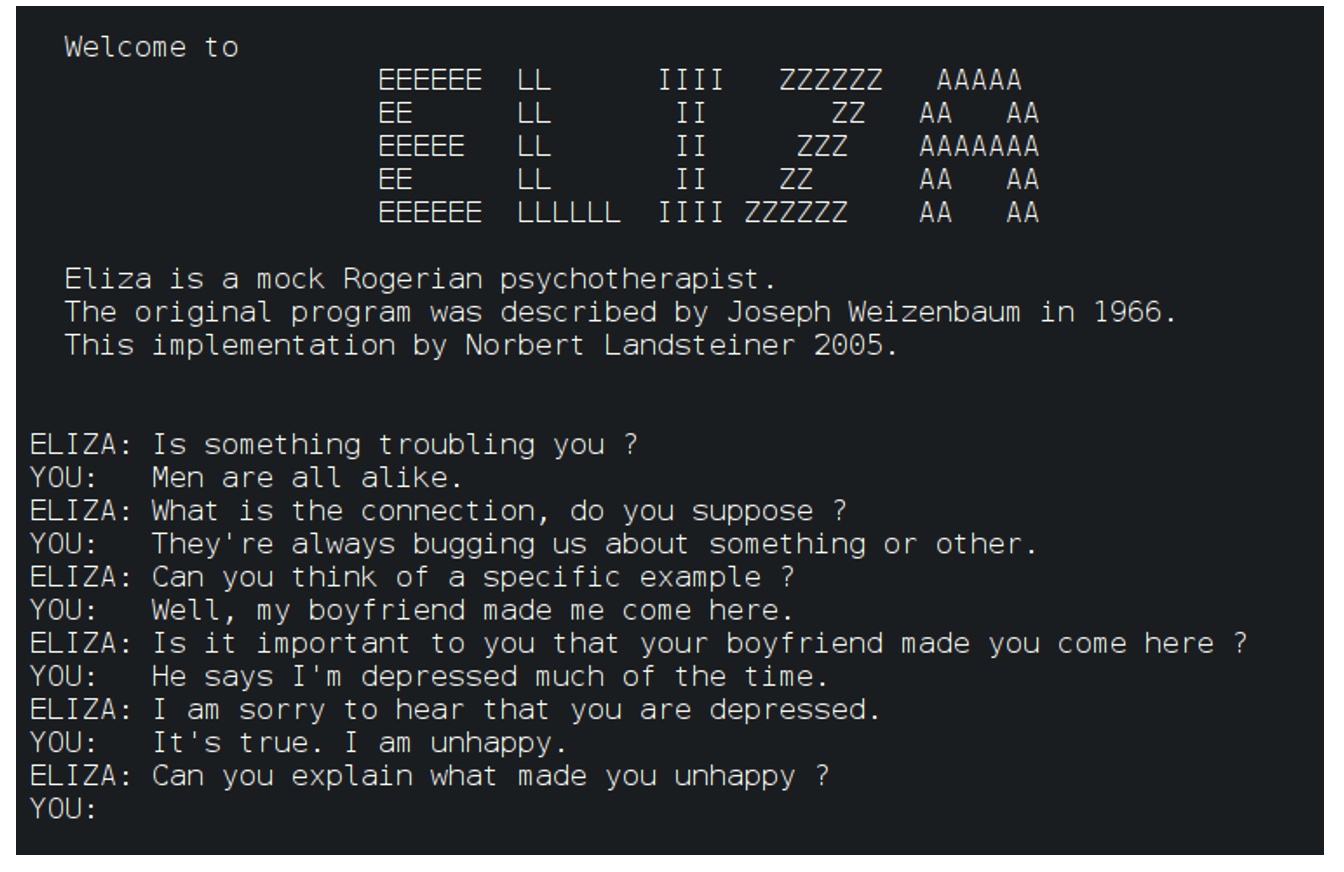
In 1966, Joseph Weizenbaum, an MIT computer scientist, wrote the world’s first chatbot, ELIZA, naming her after Eliza Doolittle in George Bernard Shaw’s play, Pygmalion.
In ancient Greek mythology, Pygmalion fell in love with one of his sculptures, which magically came to life. As Eliza Doolittle would learn to speak in a posh upper-class accent to fit into British high society, ELIZA the chatbot, was programmed to masterfully use language to give the illusion of understanding and empathising with its human user.
One of ELIZA’s abilities was coded as a script called DOCTOR, which would simulate a Carl Rogers-trained psychotherapist (AKA “person-centered” psychotherapy). Weizenbaum cleverly chose the context of psychotherapy to “sidestep the problem of giving the program a database of real-world knowledge” (Weizenbaum, 1976).
ELIZA was programmed to search for keywords in its conversations, apply weights to these keywords, and produce text output using the most important keywords from the user. It was designed to show signs of empathic listening simply by repeating the patient’s words back as open-ended questions, such as “How do you feel about XYZ?”.
Weizenbaum’s secretary was the first person to test ELIZA, after which she asked: “Would you mind leaving the room please?”, so that she could continue her private conversation with this artificial therapist.
Despite being a very simple program with only 200 lines of code, ELIZA’s deceptively intelligent responses quickly attracted many eager (and lonely) users across the MIT campus. Weizenbaum was so shocked by the success of his creation he wrote, “I had not realised … that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people.”
Figure 5: The first “online conversation” between ELIZA and PARRY in 1972

Later, in 1972, the Stanford psychiatrist Kenneth Colby wanted to create a new chatbot “like ELIZA, but with attitude”. He named it PARRY as it simulated a human patient with paranoid schizophrenia.
PARRY claimed to be one of the earliest programs to successfully pass a narrow version of the Turing Test, as a group of human psychiatrist judges were unable to tell the difference between PARRY and other human patients. Both bots, PARRY (the patient) and ELIZA (the doctor) were even set up to “chat” with each other over the ARPANET — an early predecessor of the Internet – with fascinating conversations, as Figure 5 shows.
Hopefully, this cautionary tale of the dangers of anthropomorphising machines should warn us about the limitations of any technology to avoid being fooled by its “magic”.
As Arthur C. Clarke’s 3rd law predicts, “Any sufficiently advanced technology is indistinguishable from magic”.
Stay tuned for the next article in this series, where we will further our understanding by reviewing the history of statistical language modelling by examining the seminal contributions of Andrei A. Markov and Claude E. Shannon.
References
[1] https://en.wikipedia.org/wiki/Emily_M._Bender#Contributions – https://en.wikipedia.org/wiki/Timnit_Gebru#Exit_from_Google
CPD: Actuaries Institute Members can claim two CPD points for every hour of reading articles on Actuaries Digital.




